芝能智芯出品股票配资平台app
理想Livis Day发布会,谢炎上台的开场白是:今天要跟大家聊一个困扰整个计算机行业将近20年的问题,要向你们展示一个答案,全球首款数据流AI芯片马赫M100。
1024个TOPS、5纳米工艺、双芯2560TOPS,放在2026年已经不算出圈的数字。
但掌声最密集的那几十秒,不是参数,是谢炎讲了冯·诺依曼架构用70年推动了通用计算的辉煌,马赫M100希望用数据流架构接过这一棒。
有这么玄乎吗?
推倒一座70年的房子
把芯片从冯·诺依曼架构换成数据流架构,是重新盖楼。
谢炎讲了一段历史:上世纪八九十年代,计算机行业享受着两重红利。
摩尔定律管密度,每隔两年晶体管翻倍。Dennard缩放定律管频率,晶体管缩小但电压和电流同步下降,功耗不增反减。程序员写一行代码都不用改,放两年性能自动翻倍。
2004年前后,65纳米工艺出现了一件事:晶体管的绝缘层太薄了,开始漏电、电压降不下去了,热量开始爆发。Dennard定律死了。2010年以后,摩尔定律也开始不太适用了,每代制程的性能提升从翻倍掉到三成、两成、一成。
谢炎说:"曾经驱动计算机行业的两条腿,一条断了,另一条也开始瘸了。与此同时,AI来了。"
2012年AlexNet点燃深度学习,2022年ChatGPT让全世界意识到AI没有边界,2025年Agent时代爆发,推理算力需求已经超出了任何人最疯狂的预测。算力的供给在放缓,算力的需求在增长。
冯·诺依曼架构之所以统治了70年,是因为它极其符合人类大脑一步一步推理的思维习惯。控制器、运算器、存储器、输入输出,指令一条接一条执行。
但代价是,为了管理这条指令队列,芯片需要投入海量的晶体管做缓存、调度、分支预测。
当遇到AI这种海量并行计算的时候,管理开销跟着数据量一起膨胀,效率被锁死在一个很低的天花板下。
数据流架构的思路是反过来的,AI计算天然是并行的。
数据之间的关系是确定的,流动路径是清晰的。拆掉中央式的指令队列和伴随它左右的大量管理开销,让数据流动本身来驱动计算的发生。让架构围绕AI的计算形态来原生设计。
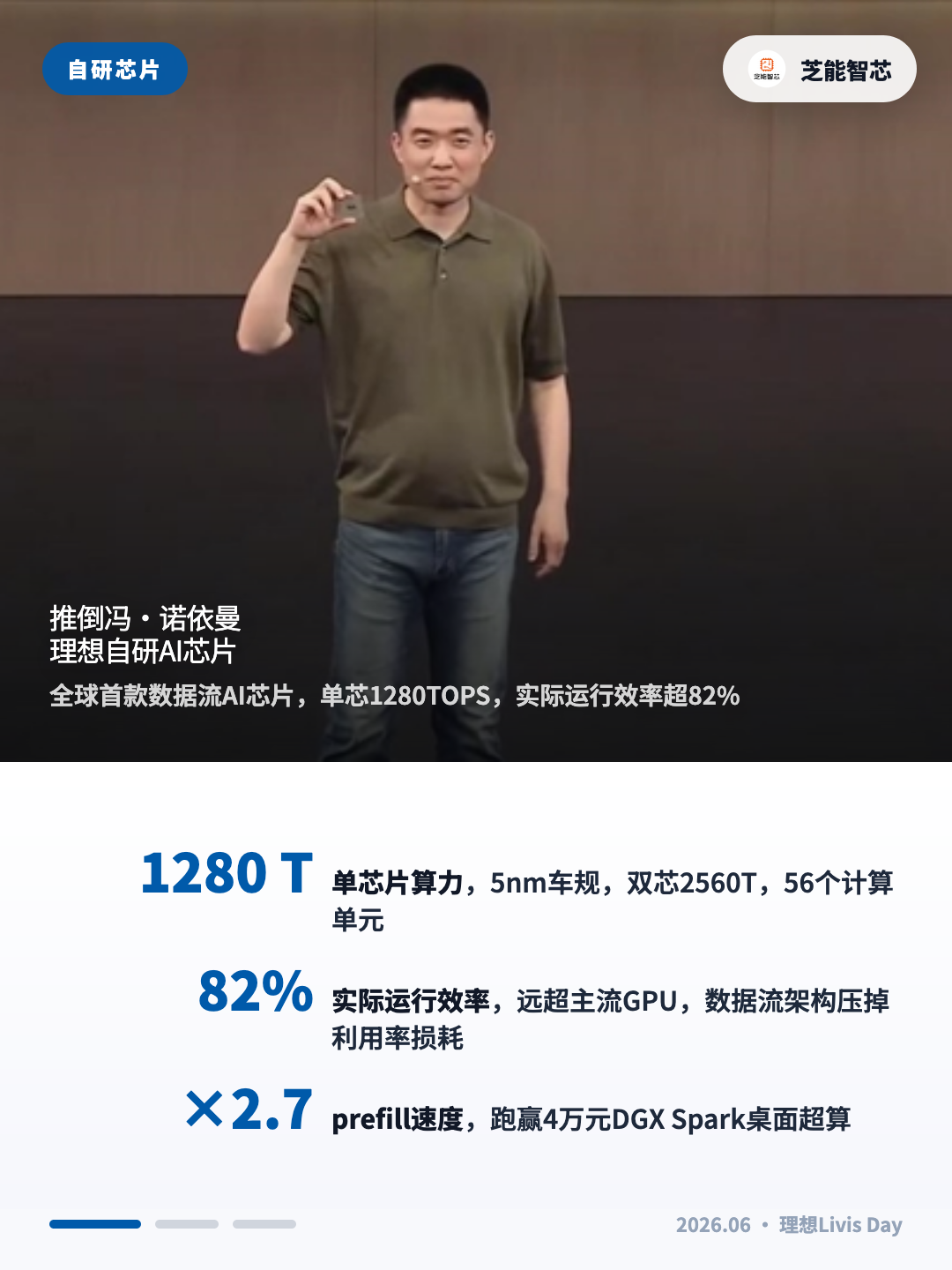
听起来抽象。落到马赫M100这颗芯片上,就是一组具体的数字。
单芯片1280TOPS,双芯2560TOPS,5纳米车规工艺。56个计算单元和一个数据处理模块,用网格总线和数据环形总线双互联架构支撑。
网格总线提供高带宽的点对点通路,数据环形总线提供确定性的广播通路。数据流到哪里,就在哪里触发计算。
CPU部分,24颗24核ARM A78AE,主频2.3GHz。8路LPDDR5X内存子系统,273GB每秒的超高带宽。实际运行效率超过82%。
谢炎只提了一句"主流基于SIMT架构的GPU做到这个数字是非常困难的"。
做过AI推理部署的人都知道,一块GPU的理论TOPS和实际跑出有效算力的比例,中间差着巨大的利用率损耗。数据流架构把这层损耗压到了最低。
和Thor直接对比,在CNN骨干网络、unAD和理想马赫VLA核心模型三项测试中,马赫M100全部超越。
谢炎说"不是略微领先,是数倍的性能差距"。
和一台售价4万元的英伟达DGX Spark桌面超算比,跑千问3.5B、3B通用大模型,prefill速度是DGX的2.7倍,decode速度是1.5倍。一台装在车里的芯片,比一台4万块的桌面超算跑得更快。
马赫M100的架构论文被ISCA 2026正式收录,谢炎说:"理想汽车是汽车行业中第一家、历史上第一家,在ISCA工业分区获得论文录取的企业。入选ISCA从来不是因为造了一颗芯片,是因为提出并实践了一种创新的架构思路。"
Part 2手眼脑全部打通后,
发生了什么
芯片是底座。放在上面的东西是什么?
除了特斯拉,国内没有智驾第一梯队,詹锟 FSD V14.3连着开了整整两个星期。回国以后,脑子里只剩了两句。第一句公开说了:"特斯拉真的太强大了。"第二句只在内部说了,因为他说自己感受到了巨大的压力。然后紧急召集核心算法团队复盘。
真正感受到压力,才证明我们是在平视这个星球上最强大的对手,而不是在国内的内卷中自我麻痹。
截至6月14日,理想全系智能驾驶主动避险总次数1727万次。其中重大避险5.5万次。1400余天,日均主动避险1.2万次。
全新马赫VLA系统的端到端时延压缩到了0.28秒。普通人从发现危险到踩刹车的平均反应时间是0.45秒。地表最强的F1车手极限反应是0.25秒。
马赫VLA比普通人快40%,和F1只差0.03秒。在120公里时速下,这0.17秒的差距等于提前6米刹停。6米是一台劳斯莱斯幻影的整车长度,而6米就是刹停到相撞、生存到毁灭的全部距离。
这个0.28秒是从光子进入传感器到车辆执行的全链路深度重构。
视觉输入时延降47%,模型推理链路缩短43%,线控底盘响应降38%,操作系统调度编排降28%。詹锟说是整个链路从头到尾都变短了。
今天的智驾会不会倒车。詹锟在台上问了一个全场没人敢正面回应的问题:"请问你们对自己的智驾的倒车能力,有一款是满意的吗。哪怕你是理想的车主,大胆面对这真实的问题。"
他放了一段视频:广州傍晚雨夜,城中村小路,路宽不到3米。没有车道线,没有交通标识,路边有打伞的行人,随时乱窜的外卖骑手,占道摆摊的小贩。马赫VLA在这种路况下没有刹停,没有犹豫,根据对象来车、行人、电动车的位置主动辗转腾挪,给每一个参与者留足了空间。
模仿学习数据规模提升50%,强化学习数据量暴增15倍,模型参数量提升10倍同时每秒token计算量提升15倍,光靠模仿你只能学到大概是这么开的,只有真实的错误砸在你的脸上,你才能真正学会这样开是对的。
Part 3AI是在车里独立完成任务
芯片管算力,模型管能力。最后是体验。
李想在开场的时候提了一个问题:今天的智能手机和智能汽车其实都不智能。他的逻辑是,传统智能汽车在安全上满足功能安全但不保护人,在能力上只会调用功能不会独立完成任务,在效率上远低于人类。这三个维度加起来,离"真正的智能"还差得很远。
他给出的定义是:一辆具身智能汽车,等于电动车加职业司机加AI计算机加生活助手。
四种能力做进一个产品里。现场做了连演示,最复杂的一个:厂长(李想)一家六口,老婆在蓝色港湾购物,老大在赵全营造学美术,老二在望京学芭蕾,老三在中关村学乐高,老四在满营打羽毛球。先去接老大,再接老四,再接老三,最后接上老二去接老婆,晚上给老四在三里屯过生日。
一段话六个地点,顺序和出发地的地理逻辑完全打乱。理想同学的Agent在十几秒内完成了所有地址的排序和路线规划。
马赫Mind-Pro是云端大模型,208TPS峰值,token消耗降低38%,工具调用冗余轮次降低47%,IFeval、LongBench V2、BFCL V4等权威基准全部第一梯队,这是真正可量化、可落地、高性价比的实战型智能体模型"。
马赫Mind-Edge是端侧原生Agent。多模态流式时序建模,让模型能连续理解动态物理世界,同时具备因果推理和自主决策能力。
彻底摆脱了传统AI只回答不行动的模式。可以说出动作,实时调用车辆硬件,always on全天候,全部在车端本地实现。低时延、高可靠,数据完全不上传。
小结
理想在AI上给出的差异化股票配资平台app,云端模型跑分,端侧模型干活。一个管深度的思考,一个管持续的陪伴。两个合在一起,车才从"回答问题"走进了"独立完成任务"。
富华配资提示:文章来自网络,不代表本站观点。